1. 인덱스
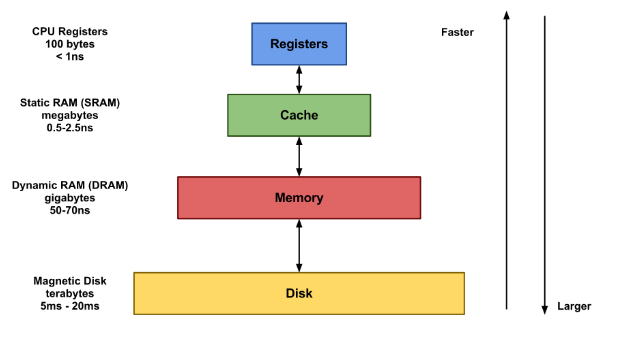
인덱스는 데이터베이스 사용자가 지정한 컬럼들을 메모리 영역에 두고 빠르게 가져다 쓰려고 생성하는 것이다.
읽기(Select Query) 성능을 향상시키기 위해 Insert, Update, Delete의 성능을 희생한 것이라고 보면 된다.
왜냐하면 읽기 성능을 위해 전체 메모리 100중에 인덱스로 20만큼 할당했다면, 쓰기 쿼리를 위한 메모리 할당량은 최대 100에서 80으로 줄어들었기 때문이다.
다만, 쓰기를 위해 해당 데이터를 Select하고 해당 작업을 하는 것은 인덱스가 있으므로 속도가 올라가게 된다.
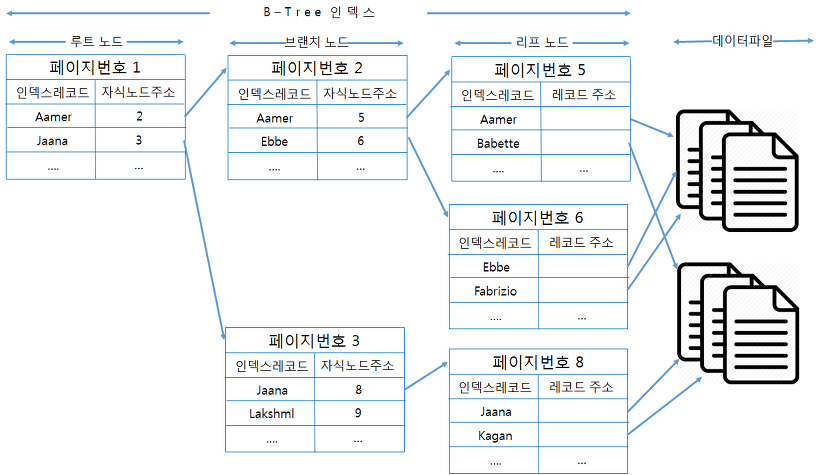
인덱스를 사용 안하고 쌩으로 데이터베이스에서 데이터를 Read하는 작업은 하위 노드가 더 계층적일수록 성능이 떨어진다.
비정규화를 많이 해서 잘게 쪼개놓으면 많은 join을 해야하니 읽기 성능을 포기하고 쓰기 성능을 향상시킨 것이다.
인덱스 성능을 향상시킨다는 것은 디스크 저장소에 접근하는 노드 계층 수가 얼마나 적느냐, 즉 Root 노드에서 Leaf 노드까지 왔다가는 횟수에 달려있다.
다만, 데이터수가 몇억개 이렇게 된다면, 비정규화된 테이블을 역정규화하거나 인덱싱을 하더라도 RDB 특성상 한계가 있어서 NoSQL 쓰는게 낫다고 함.
2. 주의점
아래의 요소로 인해 B-Tree 인덱스는 성능의 영향을 받는다.
- 인덱스를 설정할 때마다 메모리를 점유하므로 많은 수를 추천하지 않는다(3~4개가 적당)
- 인덱스 키가 길수록 성능 이슈가 발생하므로 길이를 너무 길게 하지 않도록 해야한다.
- 인덱스로 레코드를 읽는 것은 인덱스를 거치지 않고 레코드를 읽는것보다 리소스를 많이 먹는다. 손익분기점을 생각해서 인덱스를 설정해야한다.
- 유니크 키의 수도 인덱스에 영향을 줄 수 있다.
3. 데이터베이스 인덱스 테스트 환경 구축
인덱스 성능을 보기위해 real Mysql에서 제공하는 환경을 구축해보자.
나는 Mac OS 에서 도커를 띄워서 환경을 구축하려고 한다.
이미 OS에 도커가 설치되어있다고 가정한다.
git clone https://github.com/wikibook/realmysql80.git
적당한 디렉토리에서 해당 깃허브 코드를 끌어온다.
docker run --name mysql-container -e MYSQL_ROOT_PASSWORD=password -d -p 3306:3306 mysql:latest
최신버전의 mysql을 사용하며, 기존에 3306으로 mysql을 띄워놨다면 다른 포트인 3307 이렇게 띄우면 된다.
비밀번호는 password로 해놨으니 넣고 싶지 않다면 공백으로 두거나 파라미터자체를 제거하면 된다.
docker cp employees.sql mysql-container:employees.sql
docker cp create_load_database.sql mysql-container:create_load_database.sql
깃허브에서 받은 코드의 압축을 풀면 employees.sql과 creeate_load_database.sql 파일이 생성되는데, 이 파일을 도커 컨테이너인 mysql-container로 copy한다.
참고로 root 디렉토리로 복사시켰으니 경로를 :/path/create_load_database.sql 처럼 바꿔도 된다.
cp create_load_database.sql 는 생성하고 싶은 파일명이므로 바꿔도 된다.
mysql -u root -p
password : password
mysql> create datebase employees default character set utf8mb4 collate utf8mb4_0900_ai_ci;
mysql> use employees
mysql> source employees.sql
위처럼하면 복제된 파일을 가지고 테이블을 만들어서 데이터까지 삽입해준다.
mysql> show tables;
+---------------------+
| Tables_in_employees |
+---------------------+
| departments |
| dept_emp |
| dept_manager |
| employee_docs |
| employee_name |
| employees |
| employees_comp4k |
| employees_comp8k |
| salaries |
| tb_dual |
| titles |
+---------------------+
mysql> select count(*) from dept_emp;
+----------+
| count(*) |
+----------+
| 331603 |
+----------+
1 row in set (0.07 sec)
이제 테스트할 환경이 만들어졌다.
4. 인덱스와 컬럼
mysql> select count(*) from employees;
+----------+
| count(*) |
+----------+
| 300024 |
+----------+
1 row in set (0.01 sec)
mysql> desc employees;
+------------+---------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+------------+---------------+------+-----+---------+-------+
| emp_no | int | NO | PRI | NULL | |
| birth_date | date | NO | | NULL | |
| first_name | varchar(14) | NO | MUL | NULL | |
| last_name | varchar(16) | NO | | NULL | |
| gender | enum('M','F') | NO | MUL | NULL | |
| hire_date | date | NO | MUL | NULL | |
+------------+---------------+------+-----+---------+-------+
6 rows in set (0.02 sec)
mysql> show index from employees;
+-----------+------------+---------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression |
+-----------+------------+---------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| employees | 0 | PRIMARY | 1 | emp_no | A | 282839 | NULL | NULL | | BTREE | | | YES | NULL |
| employees | 1 | ix_hiredate | 1 | hire_date | A | 4991 | NULL | NULL | | BTREE | | | YES | NULL |
| employees | 1 | ix_gender_birthdate | 1 | gender | A | 4 | NULL | NULL | | BTREE | | | YES | NULL |
| employees | 1 | ix_gender_birthdate | 2 | birth_date | A | 9542 | NULL | NULL | | BTREE | | | YES | NULL |
| employees | 1 | ix_firstname | 1 | first_name | A | 1129 | NULL | NULL | | BTREE | | | YES | NULL |
+-----------+------------+---------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
5 rows in set (0.03 sec)
mysql> select count(distinct emp_no) as emp_no,
-> count(distinct birth_date) as birth_date,
-> count(distinct first_name) as first_name,
-> count(distinct last_name) as last_name,
-> count(distinct gender) as gender,
-> count(distinct hire_date) as hire_date
-> from employees;
+--------+------------+------------+-----------+--------+-----------+
| emp_no | birth_date | first_name | last_name | gender | hire_date |
+--------+------------+------------+-----------+--------+-----------+
| 300024 | 4751 | 1275 | 1637 | 2 | 5434 |
+--------+------------+------------+-----------+--------+-----------+
1 row in set (0.37 sec)
위 테이블에 대한 정보는 이렇다.
컬럼 카디널리티까지 확인할 수 있었다.
SET profiling = 1;
우선 프로파일링을 활성화해서 쿼리 실행시간을 볼 수 있도록 설정한다.
select * from employees where gender='M';
SHOW PROFILES;
| 9 | 0.26417075 | select * from employees where gender='M' |
위처럼 gender에 대한 인덱스(ix_gender_birthdate)가 걸려있을때는 0.26초가 걸린다고 한다.
그럼 인덱스를 삭제해보고 인덱스가 없을때 조회속도가 얼마나 걸리는지 확인해보자.
mysql> alter table employees drop index ix_gender_birthdate;
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> show index from employees;
+-----------+------------+--------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression |
+-----------+------------+--------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| employees | 0 | PRIMARY | 1 | emp_no | A | 282839 | NULL | NULL | | BTREE | | | YES | NULL |
| employees | 1 | ix_hiredate | 1 | hire_date | A | 4991 | NULL | NULL | | BTREE | | | YES | NULL |
| employees | 1 | ix_firstname | 1 | first_name | A | 1129 | NULL | NULL | | BTREE | | | YES | NULL |
+-----------+------------+--------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
3 rows in set (0.01 sec)
조회해보자.
select * from employees where gender='M';
mysql> show profiles;
| 18 | 0.12887775 | select * from employees where gender='M'
0.26s -> 0.12s 로 줄어들었다? 더 빨라졌다? 인덱스를 걸었는데 안걸었을 때가 더 빠르다??
그게 아니다. 완전히 틀렸다.
인덱스를 gender에 건것을 select * 로 조회했으니 메모리에 올라간 gender 외에 다른것도 다 조회하다보니
인덱스를 안것만 못한 조회속도를 가져온것이다.
mysql> CREATE INDEX ix_gender ON employees(gender);
Query OK, 0 rows affected (0.30 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> show profiles;
// gender에 Index 걸기 전
32 | 0.06800025 | select gender from employees where gender='F'
// gender에 Index 건 후
36 | 0.02339000 | select gender from employees where gender='F'
내가 어떤 인덱스를 걸었는지, 어떤 컬럼을 조회할 것인지 이것을 생각해서 조회를 해야한다.
나는 gender 컬럼에 인덱스를 걸었으니 속도 비교를 하고 싶으면 gender 컬럼을 지정해서 조회해야하는 것이다.
5. 복합인덱스
| 43 | 0.14782750 | select gender, hire_date from employees where gender = 'M' and hire_date >= '1995-01-01' |
| 44 | 0.13383725 | select hire_date, gender from employees where hire_date >= '1995-01-01' and gender = 'M' |
내 의도는 인덱스 스킵 스캔을 의도했다.
하지만 두 쿼리의 속도는 차이가 별로 나지 않았다.
mysql> show index from employees;
+-----------+------------+--------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression |
+-----------+------------+--------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| employees | 0 | PRIMARY | 1 | emp_no | A | 282839 | NULL | NULL | | BTREE | | | YES | NULL |
| employees | 1 | ix_hiredate | 1 | hire_date | A | 4991 | NULL | NULL | | BTREE | | | YES | NULL |
| employees | 1 | ix_firstname | 1 | first_name | A | 1129 | NULL | NULL | | BTREE | | | YES | NULL |
| employees | 1 | ix_gender | 1 | gender | A | 1 | NULL | NULL | | BTREE | | | YES | NULL |
+-----------+------------+--------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
4 rows in set (0.01 sec)
ix_hiredate, ix_gender 인덱스가 각각 걸려있다.
SELECT * FROM employees WHERE hire_date >= '1995-01-01' AND gender = 'M' 쿼리를 실행한다고 생각해보자.
- hire_date 열에 대한 필터링은 ix_hiredate 인덱스를 사용
- gender 열에 대한 필터링은 ix_gender 인덱스를 사용
2개가 컬럼 순서에 따라 순서대로 작동하는 것이다.
그래서 2개의 필터링 시간이 각각 들게 된다.
물론 인덱스를 걸지 않은 것보다는 빠르겠지만 이때 인덱스의 효과를 제대로 주고 싶다면 복합인덱스를 사용하는 방법이 있다.
CREATE INDEX ix_gender_hiredate ON employees(gender, hire_date);
위처럼 복합인덱스를 설정할 수 있다.
인덱스의 순서도 중요한데, 인덱스 스킵 스캔을 알아야한다.
칼럼에 대한 비교 조건의 수가 적은 컬럼을 앞에다가 둬야 row 비교 개수가 줄어든다는 점을 이해하면 된다.
gender는 M, F 2개 값 뿐이다.
반면에 hire_date는 날짜이므로 비교할 날짜가 매우 많다.
그래서 gender 컬럼을 앞에 배치한 것이다.
| 46 | 0.03050550 | alter table employees drop index ix_hiredate |
| 47 | 0.01814275 | alter table employees drop index ix_gender
우선 비교를 위해 기존에 있던 인덱스는 제거하고 실행해보자.
// ix_gender, ix_hire_date 각각 인덱스 설정해놨을 때
| 43 | 0.14782750 | select gender, hire_date from employees where gender = 'M' and hire_date >= '1995-01-01' |
| 44 | 0.13383725 | select hire_date, gender from employees where hire_date >= '1995-01-01' and gender = 'M' |
// ix_gender_hiredate로 복합인덱스 설정해놨을 때
// 컬럼 배치순서가 반대면 속도가 더 느려짐
| 50 | 0.01160100 | select gender, hire_date from employees where gender = 'M' and hire_date >= '1995-01-01' |
| 51 | 0.01595800 | select hire_date, gender from employees where hire_date >= '1995-01-01' and gender = 'M' |
// ix_gender, ix_hire_date, ix_gender_hiredate 어떠한 인덱스도 없을 때
| 53 | 0.07675475 | select hire_date, gender from employees where hire_date >= '1995-01-01' and gender = 'M' |
| 54 | 0.05543950 | select gender, hire_date from employees where gender = 'M' and hire_date >= '1995-01-01' |
위처럼 속도 차이가 나는 것을 알 수 있다.
특히, 복합인덱스로 설정해놨을 때 컬럼 배치순서가 인덱스 설정 순서와 다르다면, 인덱스를 각각 지정한것보다도 느려진다는 점을 알아야한다.
따라서 아래 사항을 생각하며 쿼리를 짜야한다.
- 2개 이상의 컬럼을 가지고 조회한다면 복합인덱스를 사용
- 컬럼의 배치 순서는 비교 컬럼의 수가 적은것을 앞에 둔다.
6. 정렬
| 56 | 0.14685350 | select hire_date from employees order by hire_date ASC |
| 57 | 0.20272175 | select hire_date from employees order by hire_date DESC |
정렬은 기본적으로 오름차순(ASC)가 내림차순(DESC)보다 빠르다.
간단하게 auto_increment가 1부터 시작한다.
그럼 조회는 1부터 시작하는 것이 당연하다.
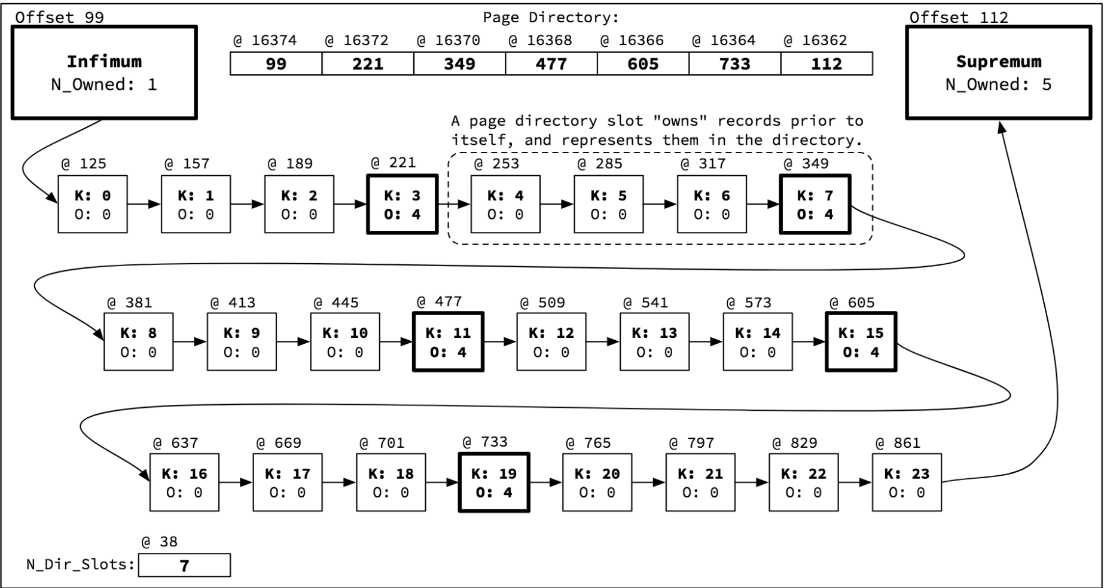
이 차이가 나는 이유는 InnoDB 스토리지 엔진은 정순 스캔과 역순 스캔의 페이지(블록) 간의 양방향 연결 고리를 통해 Forward 하는냐 Backward 하느냐의 차이에서 일어난다고 하지만, 잘 생각해보면 당연히 정순 스캔이 빠를것이다.
요약하자면, 레코드들이 단방향으로 링크를 가진 구조라서 그렇다.(1부터 끝까지 단방향 구조)
참고
MySQL 8.0 8장 인덱스
https://jojoldu.tistory.com/243
https://tech.kakao.com/2018/06/19/mysql-ascending-index-vs-descending-index/
'Database' 카테고리의 다른 글
| MySQL 메모리 영역 (0) | 2024.03.14 |
|---|---|
| Localhost와 127.0.0.1의 차이 (0) | 2024.03.12 |
| Mysql, Postgresql, Mongoose의 연결 요청 처리 방식 (0) | 2024.03.11 |
| MySQL Flush (0) | 2024.03.10 |
| MySQL Buffer Pool 조정하기 (0) | 2024.03.09 |